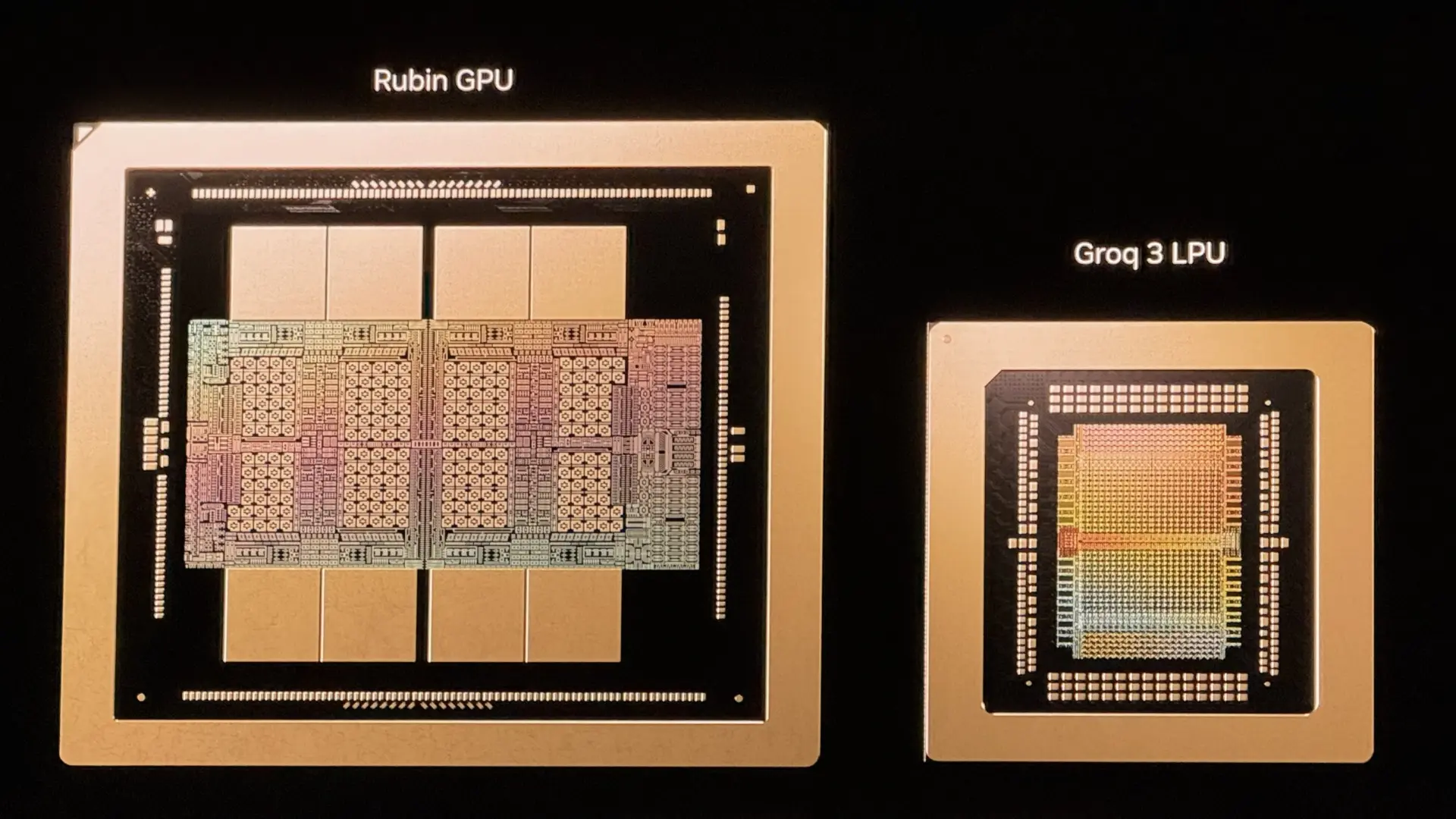
Nvidia'nın CEO'su Jensen Huang tarafından "fabrika" olarak adlandırılan yeni nesil yapay zeka veri merkezlerini güçlendirmesi beklenen Vera Rubin platformu, bu yılın sonlarına doğru piyasaya sürülecek. Huang, bugün gerçekleştirdiği GTC etkinliğinde, Nvidia'nın geçen yıl Groq'tan satın aldığı teknolojiyi kullanarak Rubin platformunun yeteneklerini nasıl genişlettiğini duyurdu. Rubin platformuna eklenen yeni Nvidia Groq 3 LPU, yapay zeka modellerinin en üst düzeyinde düşük gecikme süresi ve yüksek etkileşim için tokenların yoğun bir şekilde sunulmasını sağlayan bir çıkarım hızlandırıcısı olarak öne çıkıyor.
Rubin platformu daha önce de Rubin GPU'su, Vera CPU'su, NVLink 6 ölçek yükseltme anahtarları, ConnectX 9 akıllı ağ arabirimi kartı, Bluefield 4 veri işleme birimi ve Spectrum-X ölçek genişletme anahtarı gibi altı farklı çipi barındırıyordu. Groq 3 LPU'nun eklenmesiyle Rubin platformu, ölçeklenebilir bir yapı taşı daha kazanmış oluyor.
Çoğu yapay zeka hızlandırıcısının çalışma belleği olarak HBM kullanmasının aksine, her Groq 3 LPU 500 MB SRAM barındırıyor. Bu bellek, CPU ve GPU'lardaki ultra yüksek hızlı önbelleklerde kullanılanla aynı türdedir. Her bir Rubin GPU'sundaki 288GB HBM4'e kıyasla daha küçük görünse de, bu SRAM, bahsi geçen HBM'nin 22 TB/s'lik bant genişliğinin çok üzerinde, 150 TB/s bant genişliği sunuyor. Bu muazzam bant genişliği artışı, özellikle bant genişliğine duyarlı yapay zeka kod çözme işlemleri için çıkarım uygulamalarına önemli avantajlar sağlıyor.
Nvidia, 256 adet Groq 3 LPU'dan oluşan Groq 3 LPX sunucularını inşa edecek. Bu sunucular, çıkarım hızlandırma için 128 GB SRAM ve 40 PB/s bant genişliği sunarken, sunucular arasındaki bağlantı için her bir sunucu başına 640 TB/s'lik özel bir ölçek yükseltme arayüzüne sahip olacak.
Nvidia, Groq LPX'i Rubin için bir yardımcı işlemci olarak konumlandırıyor. Bu sayede, yapay zeka modellerinin her katmanında ve her tokenda kod çözme performansını artırması hedefleniyor. Bu gelişme, Rubin platformunu, trilyonlarca parametreli modelleri çıkarırken milyonlarca tokenlık bağlam pencereleriyle etkileşimli performans sunması gereken çok ajanlı sistemler gibi yapay zekanın yeni sınırlarına hazırlıyor.
Çok ajanlı sistemlerdeki yapay zeka ajanlarının insanlarla etkileşiminden ziyade diğer yapay zekalarla daha fazla iletişim kurmaya başlamasıyla birlikte, yanıt verme gereksinimlerinin sınırları da değişiyor. Bir insan için makul kabul edilebilecek token üretme hızı, bir yapay zeka ajanı için oldukça yavaş kalabilir. Yeni nesil çok ajanlı sistemlerde, Rubin GPU'ları ve Groq LPU'larının birleşimi, saniyede 100 tokenlık makul bir çıktının, yapay zeka ajanları arası iletişim için saniyede 1500 token veya daha fazlasına ulaşan bir dünya vaat ediyor.
Groq 3 LPU'nun Rubin platformuna dahil olması, platformun düşük gecikmeli çıkarım alanındaki rekabette önemli bir avantaj sağlamasına yardımcı olabilir. SRAM ve işlem gücünü bir araya getirerek düşük gecikmeli çıkarım sunan Cerebras gibi rakipler, GPU'ların bu alandaki dezavantajları konusunda Nvidia'yı sık sık zorluyordu. Hatta OpenAI gibi büyük müşteriler bile bazı gelişmiş modelleri için Cerebras'ın sunduğu uygun gecikme süresinden faydalanmak üzere anlaşmalar yapmıştı.
Ayrıca, Groq 3 LPU'nun Rubin CPX çıkarım hızlandırıcısının rolünü azaltabileceği de ima edildi. Şirketin şu anki odağının Groq 3 LPX sunucusunu Rubin ile entegre etmek olduğu belirtildi. Bu odak kayması, her iki çipin de benzer çıkarım performansı iyileştirmeleri sunması ve Groq LPU'nun Rubin CPX modüllerinin gerektirdiği büyük miktarda GDDR7 belleğe ihtiyaç duymaması nedeniyle mantıklı görünüyor.