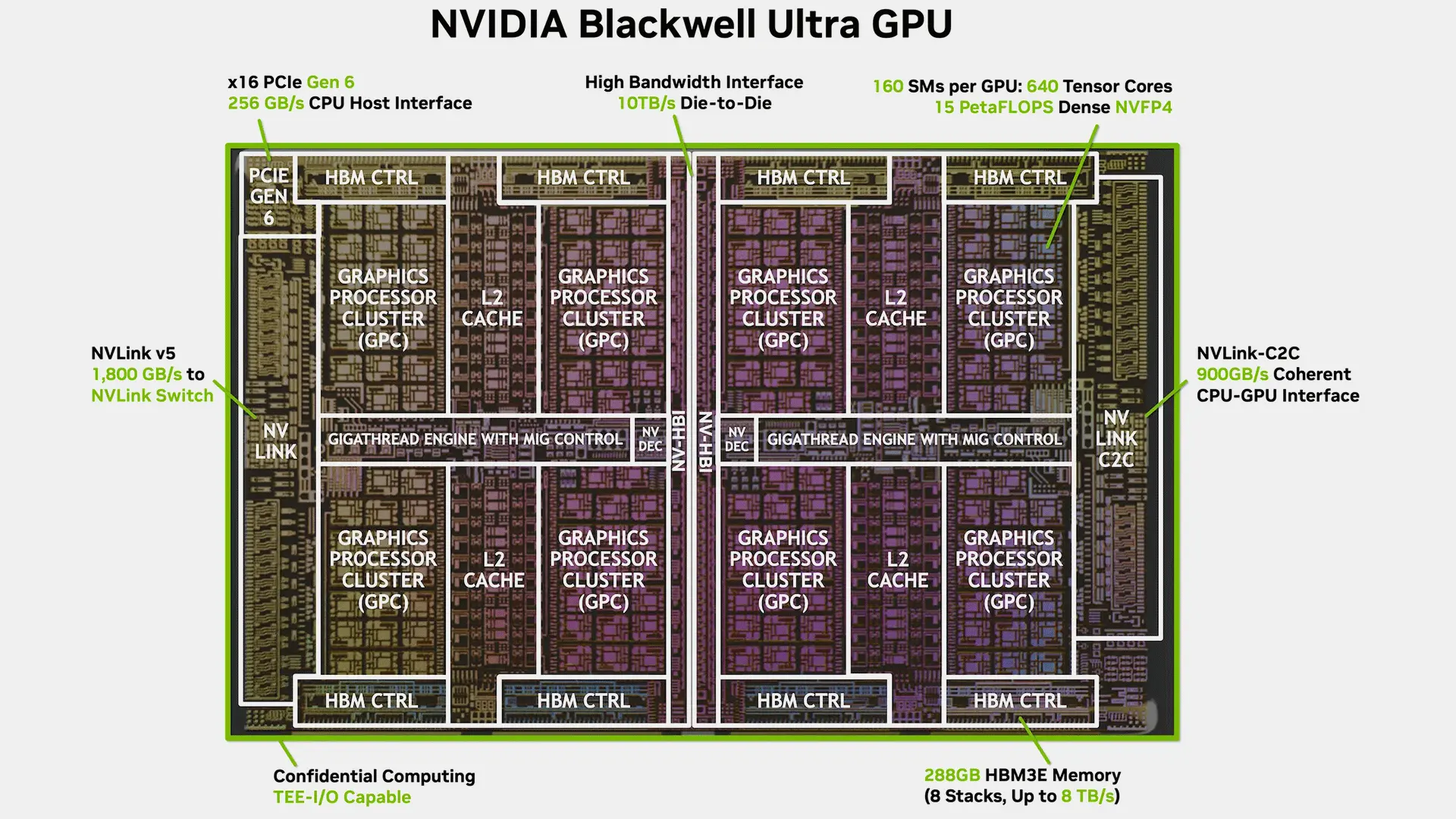
Nvidia ve iş ortakları, bir süre önce Grace CPU'lu GB300 ve x86 CPU'lu B300 sistemlerini kullanıma sundu. Şimdi ise Hot Chips 2025 konferansında, şirketin Blackwell Ultra mimarisi ve bu mimarinin uygulamasının bazı ek detayları paylaşıldı.
Genel olarak, Nvidia'nın Blackwell tabanlı B100/B200 ve Blackwell Ultra tabanlı B300 GPU'ları birbirine oldukça benziyor. Ancak Blackwell Ultra B300 serisi, özellikle NVFP4 veri formatı için optimize edilmiş yeni Tensor çekirdekleri sunuyor. Bu sayede, INT8 ve FP64 performansından ödün vererek, NVFP4 PetaFLOPS (yoğun) performansında %50'ye varan artış sağlıyor. Ayrıca, 288 GB HBM3E belleğe (186 GB'den fazla) sahip ve ana bilgisayar CPU'ları için PCIe 6.x bağlantısını resmi olarak destekliyor (PCIe 5.0'a karşılık). Bu farklılıklar, 1.400W'a karşılık 1.200W olan TDP'de 200W'lık bir artışla birlikte geliyor.
NVFP4: Nvidia'nın Özel Donanım Hızlandırmalı Özel Veri Formatı
Nvidia, Blackwell işlemcilerini 2024'ün başlarında tanıttığında, hepsinin hem yapay zeka çıkarımı hem de yapay zeka ön eğitimi için faydalı olabilecek bir FP4 veri formatını desteklediğini açıklamıştı. FP4, IEEE 754 standardıyla uyumluluğu koruyan en küçük format olarak biliniyor (1 bit işaret, 2 bit üs, 1 bit mantis). Bu, INT4'ten daha fazla esneklik sağlarken, FP8 veya FP16 formatlarından daha az hesaplama gücü gerektiriyor. Ancak Nvidia'nın Blackwell ve Blackwell Ultra'sında standart bir FP4 değil, şirketin kendi özel NVFP4 formatı kullanılıyor.
NVFP4, Nvidia tarafından Blackwell işlemcileri için tasarlanmış, hem eğitim hem de çıkarım iş yüklerinin güç verimliliğini artırmayı amaçlayan özel bir 4-bit kayan nokta formatıdır. Bu format, kompakt kodlama ile çok seviyeli ölçeklemeyi birleştirerek, BF16 doğruluğuna yakın sonuçlar verirken performans ve bellek kullanımında kazanç sağlıyor. Bu da onu hem eğitim hem de çıkarım için özellikle uygun hale getiriyor.
Geleneksel FP4 gibi, Nvidia'nın NVFP4'ü de -6 ile +6 arasında bir sayısal aralık sağlamak için kompakt bir E2M1 yerleşimi (1 bit işaret, 2 bit üs, 1 bit mantis) kullanıyor. Ancak bu kadar küçük bir formatın sınırlı dinamik aralığını ele almak için Nvidia, ikili bir ölçekleme yaklaşımı eklemiş durumda: Her 16 FP4 değerlik grubuna FP8 (E4M3) olarak saklanan bir ölçek faktörü atanırken, tüm tensöre küresel bir FP32 tabanlı faktör uygulanıyor. Nvidia'ya göre bu iki kademeli sistem, dört bitin sunduğu performans verimliliğini kaybetmeden sayısal gürültüyü düşük tutuyor.
Doğruluk açısından, Nvidia'nın dahili sonuçları, FP8'e kıyasla sapmaların genellikle %1'in altında olduğunu ve birçok iş yükünde, daha küçük blokların değer dağılımlarına daha yakından uyum sağlaması nedeniyle performansın artabileceğini iddia ediyor. Bellek gereksinimlerinin de önemli ölçüde azaldığı belirtiliyor: FP8'den yaklaşık 1.8 kat daha az ve FP16'dan ise 3.5 kat daha az. Bu, NVLink ve NVSwitch ağları boyunca depolama ve veri taşıma yükünü azaltıyor. Büyük kümeler oluşturan geliştiriciler için bu, donanım sınırlarını aşmadan daha büyük toplu iş boyutları ve daha uzun diziler çalıştırmak anlamına geliyor.
Çıkarım ve Eğitim İş Yükleri
Nvidia'nın Blackwell veri merkezi GPU'ları hakkındaki pazarlama materyallerinin çoğu, B200 ve B300 işlemcilerinin çıkarım performansının önceki nesillere göre güçlü olduğunu gösteriyor. Nvidia'nın B200 Blackwell GPU'larında OpenAI GPT-OSS 120B modeliyle yaptığı testler, çıktı hacminde herhangi bir ödün vermeden etkileşimde dört kata kadar daha hızlı bir performans iddia ediyor. DeepSeek-R1 671B modelinin bir GB200 NVL72 rafında konuşlandırılmasıyla, işlemci başına çıktı hacminin 2.5 kat arttığı ve çıkarım maliyetinin yükselmediği öne sürülüyor. Token gecikmesinin genel kapasite kadar kritik olduğu daha hızlı akıl yürütme modellerine olan talebin artmasıyla birlikte, Blackwell bu alanda beklentileri karşılıyor gibi görünüyor. Elbette Nvidia'nın iddialarının gerçek dünya kullanımında da geçerli olması şartıyla.
Ancak NVFP4 yalnızca çıkarımla sınırlı değil; Nvidia bunu trilyon token ölçeğinde ön eğitim için uygun ilk 4-bit kayan nokta formatı olarak sunuyor. 200 milyar token üzerinde eğitilmiş 7 milyar parametreli bir modelle yapılan erken deneylerde BF16 ile karşılaştırılabilir sonuçlar alındığı iddia ediliyor. Bu, ileri geçişte en yakına yuvarlama kullanılırken, geri yayılım ve güncelleme adımlarında stokastik yuvarlamanın uygulanmasıyla mümkün oluyor. Sonuç olarak NVFP4, çıkarım için mükemmel bir dağıtım iyileştirmesi olmanın yanı sıra, tüm yapay zeka yaşam döngüsü için potansiyel olarak uygun bir format haline geliyor. Bu durum, büyük ölçekli yapay zeka veri merkezleri için önemli maliyet ve enerji tasarrufu anlamına gelebilir.
Açık Kaynak Kümelerine Entegre Edildi
NVFP4 özel bir format olmasına rağmen, Nvidia bunu açık kütüphanelere dahil ediyor ve önceden nicelenmiş modeller yayınlıyor. Cutclass (GPU çekirdek şablonları), NCCL (çoklu GPU iletişimi) ve TensorRT Model Optimizer gibi çerçeveler şimdiden NVFP4'ü destekliyor. Bu arada, NeMo, PhysicsNeMo ve BioNeMo gibi daha üst düzey çerçeveler, büyük dil, fizik tabanlı ve yaşam bilimleri modelleri için bu yetenekleri genişletiyor. NVFP4 ayrıca Nemotron akıl yürütme LLM'si, Cosmos fiziksel yapay zeka modeli ve robotik için Isaac GR00T görüşe dayalı dil eylem modelinde de destekleniyor.
Yalnızca Nvidia Donanımında Mevcut: Blackwell Ultra ile %50 Performans Artışı
NVFP4, çıkarım ve eğitim için birçok avantaj sunarken ve açık kaynak çerçevelerine entegre edilirken, şu anda yalnızca Nvidia tarafından destekleniyor. NVFP4'ün diğer bağımsız donanım satıcıları (IHV) tarafından desteklenmesi pek olası değil. Bu durum, geniş bir donanım yelpazesinde çalışabilen modeller oluşturmaya çalışan geliştiriciler (özellikle büyük ölçekli kullanıcılar) için çekiciliğini azaltabilir.
Nvidia bu sorunun farkında ve NVFP4'ün yalnızca veri merkezi donanımında değil, aynı zamanda geniş bir Blackwell işlemcisi yelpazesinde de desteklendiğini belirtiyor. Sunucular için B100/B200 ve B300 işlemcilerine ek olarak, DGX Spark makineleri için GB10 çözümü ve GeForce RTX 5090 de NVFP4'ü tam olarak destekliyor; ancak Nvidia, bu durumun GB102 tabanlı tüm ürünler için geçerli olup olmadığını belirtmedi.
Buna rağmen, yalnızca Nvidia'nın B300 GPU'ları, NVFP4 performansını önemli ölçüde artıran ve diğer formatlardaki (INT8 ve FP64 gibi) performanstan ödün veren NVFP4 optimize Tensor çekirdeklerine sahip.
PCIe 6. Nesil Desteğine Sahip İlk Resmi GPU
NVFP4'te %50'lik bir performans artışı sunmasının ve 288 GB HBM3e bellek taşımasının yanı sıra, Nvidia'nın Blackwell Ultra'sı, ana bilgisayar CPU'su ile PCIe 6.x bağlantısını destekleyen ilk veri merkezi GPU'su olarak öne çıkıyor. Şu anda bu yeteneğe sahip tek işlemci Grace. PCIe 6.0, PAM4 sinyalleme ve FLIT tabanlı kodlama sayesinde x16 yuvası başına çift yönlü bant genişliğini 128 GB/s'ye çıkarıyor. Bu, yapay zeka sunucuları ve yapay zeka kümeleri için büyük önem taşıyor. GPU'nun CPU, SSD veya NIC'den veri alma hızını ikiye katlayarak, PCIe 6.0 tüm kümenin performansını hızlandırıyor ve bunun değeri göz ardı edilemez. Maalesef Nvidia, PCIe 6.x ile ilgili diğer performans iyileştirmelerini açıklamadı, ancak bunların oldukça önemli olması bekleniyor. Tüm bu detaylar, Blackwell Ultra'yı yapay zeka ve veri merkezi iş yükleri için yüksek performanslı bir çip olarak gösteriyor ve NVFP4, büyük ölçekli kullanıcıların Nvidia'yı diğer üreticiler yerine tercih etmeleri için başka bir cazip neden sunuyor.






