Geçtiğimiz aylarda Apple araştırmacılarının yayımladığı bir çalışma, yapay zeka modellerinin 'akıl yürütme' yeteneklerine dair önemli soruları gündeme getirdi. Çalışma, 'simüle akıl yürütme' olarak adlandırılan modellerin, daha önce hiç karşılaşmadıkları ve sistematik düşünme gerektiren yeni problemlerle karşılaştıklarında, çıktılarının genellikle eğitim verilerindeki örüntüleri eşleştirmekten ibaret olduğunu öne sürüyor.
Bu bulgular, daha önce başka araştırmacılar tarafından yapılan ve aynı modellerin yeni matematiksel kanıtlarda düşük başarı gösterdiğini ortaya koyan çalışmalarla benzerlik taşıyor. Her iki araştırma da, karmaşık ve kapsamlı sistematik akıl yürütme gerektiren problemler karşısında bu modellerin performansında ciddi düşüşler yaşandığını belgeledi.
“Düşünme İllüzyonu: Problem Karmaşıklığı Merceğinden Akıl Yürütme Modellerinin Güçlü Yönlerini ve Sınırlılıklarını Anlamak” başlıklı yeni Apple çalışması, 'büyük akıl yürütme modelleri' (LRM) olarak adlandırdıkları, adım adım problem çözmeye yardımcı olduğu düşünülen 'zincirleme düşünme' benzeri metin çıktıları üreterek mantıksal bir akıl yürütme sürecini simüle etmeye çalışan modelleri inceledi.
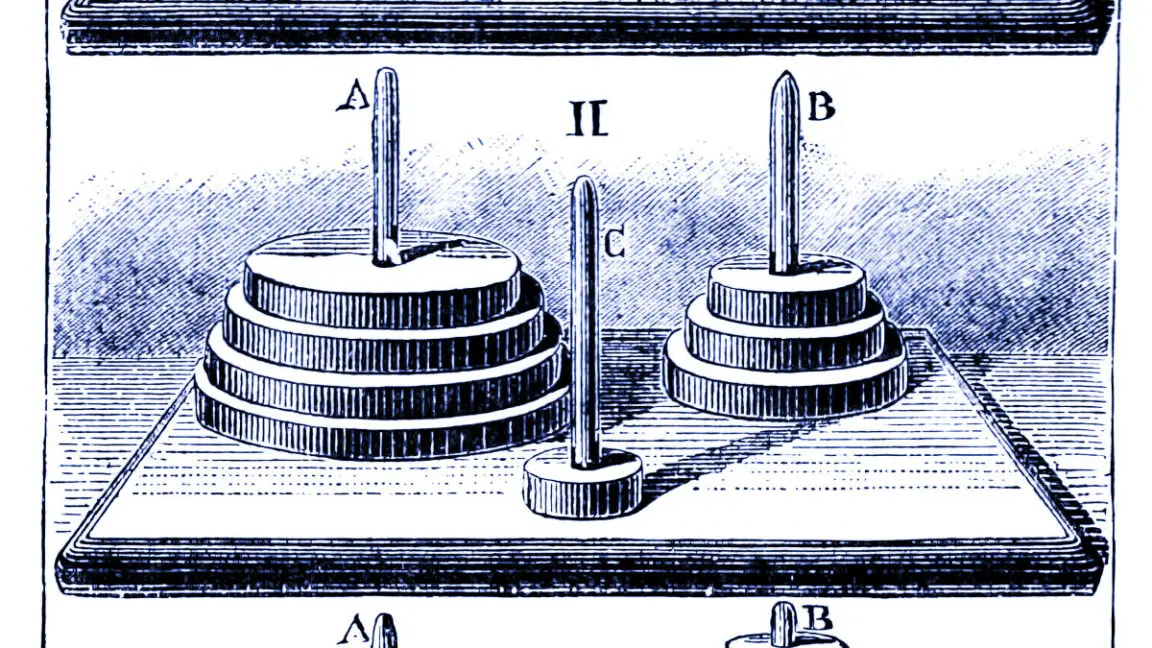
Araştırmacılar, yapay zeka modellerini dört klasik bulmacaya karşı yarıştırdı: Hanoi Kuleleri (diskleri çubuklar arasında taşıma), dama atlama (taşları eleme), nehir geçme (kısıtlamalı eşya taşıma) ve blok dünyası (blokları üst üste yığma). Bu bulmacaların zorluk seviyeleri, çok kolaydan (bir diskli Hanoi gibi) aşırı komplekse (bir milyondan fazla hamle gerektiren 20 diskli Hanoi gibi) kadar ölçeklendirildi.
Araştırmacılar, güncel değerlendirmelerin genellikle yerleşik matematik ve kodlama kıyaslamalarına odaklandığını ve yalnızca nihai doğru cevabın önemli olduğunu belirtiyor. Yani, mevcut testler modelin cevabı eğitim verisindeki örneklerden mi bulduğunu, yoksa gerçekten akıl yürüterek mi ulaştığını sorgulamıyor.
Nihayetinde, Apple araştırmacıları, daha önceki araştırmaların bulgularıyla tutarlı sonuçlar elde etti. Simüle akıl yürütme modellerinin yeni matematiksel kanıtlarda genellikle yüzde 5'in altında başarı gösterdiği, sadece bir modelin yüzde 25'e ulaştığı ve yaklaşık 200 denemede tek bir kusursuz kanıtın bile olmadığı görüldü. Her iki araştırma ekibi de, kapsamlı sistematik akıl yürütme gerektiren problemler karşısında performansın önemli ölçüde düştüğünü belgeledi.
Yaygın Şüpheler ve Yeni Kanıtlar
Yapay zeka alanında, sinir ağlarının eğitim verisi dışındaki durumlara genelleme yapmakta zorlandığını uzun süredir savunan bazı eleştirmenler, Apple'ın sonuçlarını 'büyük dil modelleri için yıkıcı' olarak yorumladı. Bu eleştirmenler yıllardır benzer argümanlar öne sürse de, yeni araştırma bu eleştirilere taze ve ampirik destek sağlıyor.
'Büyük dil modellerinin Hanoi Kuleleri gibi basit bir bulmacayı bile güvenilir bir şekilde çözememesi utanç verici' yorumları yapıldı. Hatta araştırmacılar, Hanoi Kuleleri'ni çözmek için açık algoritmalar sunsa bile model performansının artmadığı gözlemlendi. Bazı araştırmacılar bu durumun, modellerin sürecinin mantıksal veya zeki olmadığını gösterdiğini savundu.
Apple ekibi, simüle akıl yürütme modellerinin, bulmaca zorluğuna bağlı olarak 'standart' modellerden farklı davrandığını tespit etti. Birkaç diskli Hanoi gibi kolay görevlerde, standart modeller aslında daha başarılı oldu çünkü simüle akıl yürütme modelleri 'aşırı düşünerek' yanlış cevaplara yol açan uzun düşünce zincirleri üretiyordu. Orta derecede zor görevlerde ise simüle akıl yürütme modellerinin metodik yaklaşımı onlara avantaj sağladı. Ancak 10 veya daha fazla diskli Hanoi dahil olmak üzere gerçekten zor görevlerde, her iki model türü de tamamen başarısız oldu ve ne kadar süre verilirse verilsin bulmacaları tamamlayamadı.
Araştırmacılar ayrıca 'sezgisel olmayan bir ölçeklendirme sınırı' belirledi. Problem karmaşıklığı arttıkça, simüle akıl yürütme modelleri başlangıçta daha fazla 'düşünme' tokeni üretiyor, ancak bir eşiğin ötesinde, yeterli işlem kaynaklarına sahip olmalarına rağmen akıl yürütme çabalarını azaltıyorlardı.
Çalışma ayrıca, modellerin nasıl başarısız olduğuna dair şaşırtıcı tutarsızlıkları ortaya çıkardı. Bazı modeller Hanoi Kuleleri'nde 100'e kadar doğru hamle yapabilirken, toplamda daha az hamle gerektiren bir nehir geçme bulmacasında sadece beş hamle sonra başarısız oldu. Bu durum, başarısızlıkların salt hesaplama yetersizliğinden ziyade göreve özgü olabileceğini düşündürüyor.
Farklı Yorumlar Ortaya Çıkıyor
Ancak, tüm araştırmacılar bu sonuçların temel akıl yürütme sınırlılıklarını gösterdiği yorumuna katılmıyor. Bazı ekonomistler ve yazılım mühendisleri, gözlemlenen sınırlamaların modellerin doğal yetersizliklerinden ziyade, kasıtlı eğitim kısıtlamalarını yansıtabileceğini savunuyor. Örneğin, bir modele bir saat sürecek bir problemi beş dakikada çözmesi söylenirse, muhtemelen yaklaşık bir çözüm veya bir kestirme yol önerecektir. Bu durumun, pekiştirmeli öğrenme (reinforcement learning) yoluyla modellerin aşırı hesaplamadan kaçınacak şekilde özel olarak eğitilmesiyle ilgili olabileceği öne sürülüyor.
Bazı kaynaklar, sektördeki açıklanmayan kıyaslamaların, 'çıkarım için kullanılan token sayısını artırdıkça performansın neredeyse her problem alanında kesin olarak arttığını' gösterdiğini iddia ediyor. Ancak yaygın kullanımdaki modellerin, basit sorgularda 'aşırı düşünmeyi' önlemek amacıyla bu yeteneği bilinçli olarak sınırladığı belirtiliyor. Bu bakış açısı, Apple makalesinin temel akıl yürütme sınırlarını değil, mühendislik ürünü kısıtlamaları ölçüyor olabileceğini düşündürüyor.
Diğer araştırmacılar ise bu tür bulmaca tabanlı değerlendirmelerin büyük dil modelleri için uygun olup olmadığını sorguluyor. Bazı uzmanlar, Hanoi Kuleleri yaklaşımının büyük dil modellerini uygulamak için 'pek mantıklı bir yol olmadığını' belirtiyor ve başarısızlıkların akıl yürütme eksikliğinden ziyade, modellerin işlem yapabileceği maksimum metin miktarı olan bağlam penceresinde (context window) yetersiz kalmasından kaynaklanabileceğini düşünüyor. Bu makalenin, 'karşı konulmaz manşeti' (yapay zekanın akıl yürütmediği iddiası) nedeniyle abartılı bir ilgi görmüş olabileceği yorumları yapılıyor.
Apple araştırmacılarının kendileri de çalışmalarının sonuçlarını aşırı genellemekten kaçınıyor. Kendi sınırlılıkları bölümünde, 'bulmaca ortamlarının akıl yürütme görevlerinin dar bir dilimini temsil ettiğini ve gerçek dünya veya bilgi yoğun akıl yürütme problemlerinin çeşitliliğini yakalayamayabileceğini' kabul ediyorlar. Makale ayrıca, akıl yürütme modellerinin 'orta karmaşıklık' aralığında iyileşme gösterdiğini ve bazı gerçek dünya uygulamalarında fayda sağlamaya devam ettiğini belirtiyor.
Çıkarımlar Tartışmalı Kalıyor
Peki, yapay zeka akıl yürütme modelleri hakkındaki iddiaların güvenilirliği bu çalışmalarla tamamen yok mu oldu? Zorunlu olarak hayır.
Bu çalışmaların işaret ettiği şey, simüle akıl yürütme modellerinin kullandığı kapsamlı bağlam tabanlı yöntemlerin, bazılarının umduğu gibi genel yapay zekaya giden bir yol olmayabileceği olabilir. Bu durumda, daha sağlam akıl yürütme yeteneklerine ulaşmanın yolu mevcut yöntemlerin iyileştirilmesinden ziyade temelden farklı yaklaşımlar gerektirebilir.
Yukarıda da belirtildiği gibi, Apple çalışmasının sonuçları yapay zeka topluluğunda büyük etki yarattı. Üretici yapay zeka (generative AI) tartışmalı bir konu ve modellerin genel faydası üzerine süregelen ideolojik bir savaşta birçok insan aşırı pozisyonlara yöneliyor. Üretici yapay zeka savunucularının birçoğu Apple'ın sonuçlarına karşı çıkarken, eleştirmenler çalışmayı büyük dil modellerinin güvenilirliği için kesin bir darbe olarak gördü.
Apple'ın sonuçları, önceki benzer bulgularla birleştiğinde, bu sistemlerin pazarlamasının düşündürebileceği türden sistematik akıl yürütmeden ziyade, karmaşık örüntü eşleştirmeye dayandığı yönündeki eleştirileri güçlendiriyor gibi görünüyor. Adil olmak gerekirse, üretici yapay zeka alanı o kadar yeni ki, mucitleri bile bu tekniklerin nasıl veya neden çalıştığını tam olarak anlamış değiller. Bu arada, yapay zeka şirketleri akıl yürütme ve zeka çığır açan iddialarını biraz yumuşatarak güven inşa edebilirler.
Ancak bu, yapay zeka modellerinin işe yaramaz olduğu anlamına gelmez. Karmaşık örüntü eşleştirme makineleri bile, sınırlılıkları ve hataları anlaşıldığında, kullanıcıları için iş gücünden tasarruf sağlayan görevleri yerine getirmede faydalı olabilir. Eleştirmenler bile, 'en azından önümüzdeki on yıl boyunca, büyük dil modellerinin (çıkarım zamanı 'akıl yürütmeli' veya akıl yürütmesiz), özellikle kodlama, beyin fırtınası ve yazma gibi alanlarda kullanımları olmaya devam edeceğini' kabul ediyor.